



Cientos de sacrificios, puede que miles, se han cometido en contra de las cookies en los últimos años en blogs, televisión y prensa. Calificadas de malignas, falsas, inseguras, abusivas, que asaltan nuestra privacidad, espían nuestros movimientos, nos rastrean, parecen dotadas de vida propia, son virus, gusanos informáticos, unos entes con personalidad propia que se agazapan entre las www y aprovechan cualquier click para instalarse en nuestros dispositivos y robarnos el alma en silencio. Incluso perseguidas por la Ley, todavía queda un largo camino en esta lucha contra la erradicación de las cookies.
¿Por qué existen las cookies?
Las cookies son una extensión del protocolo HTTP que permite, entre otras cosas, implementar la capa de sesión del modelo OSI. Ahora ya queda todo más claro pero vamos un poco más despacio.
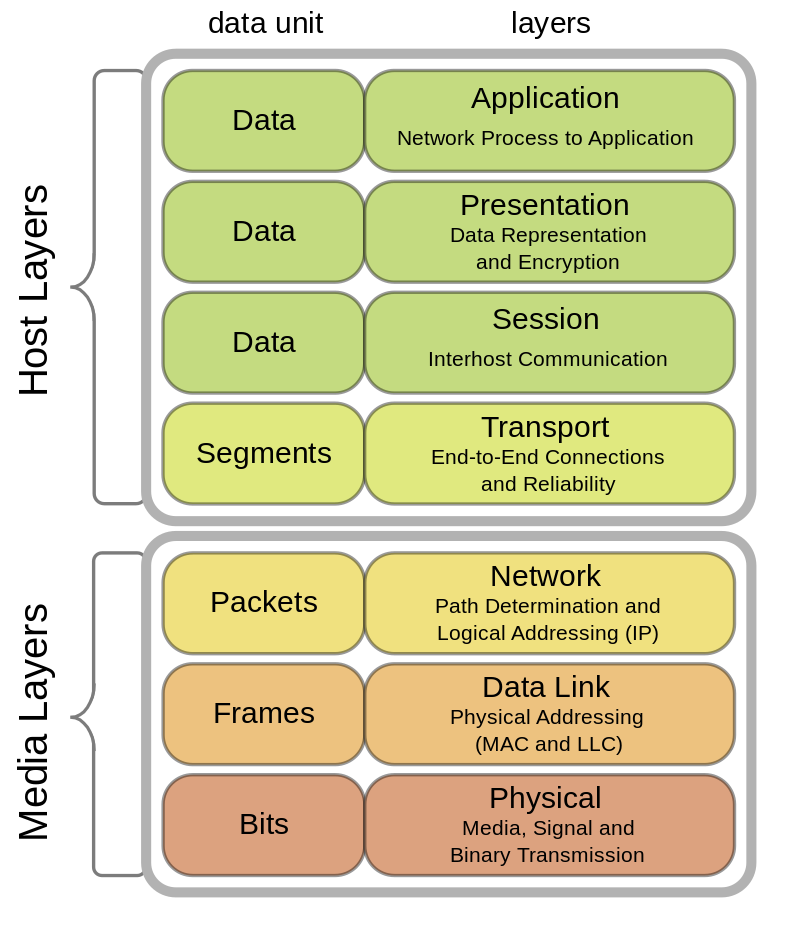
El modelo OSI
Según se investigaba y desarrollaba Internet, los creadores de la red se dieron cuenta que para establecer una comunicación entre sistemas, podían dividir el problema en partes para resolverlo más fácilmente.
{kind=link}
Cada una de esas partes se denominan capa y se coloca una encima de otra formando una especie de pila. Cada capa provee una serie de capacidades a la capa superior y evita la necesidad de conocer el resto de capas inferiores.
La capa física, encargada de transmitir bits por un medio físico, es la primera de todas, sobre ella están la de enlace, red y transporte.
La capa de transporte ya es lo suficientemente interesante como para enviar sobre ella prácticamente cualquier tipo de información, ya que provee de comunicación fiable entre dos puntos de la red. Esta capa se presenta en dos variantes: orientado a conexión y no orientado a conexión, y sus mundialmente utilizadas implementaciones TCP y UDP respectivamente.
Sobre la capa de transporte se encuentran la capa de sesión, la de presentación y la de aplicación, justo la que utilizan los usuarios. Como ya habrás adivinado, estas tres capas ya no resuelven comunicación y típicamente se mezclan en una única capa, la de Aplicación.
El protocolo HTTP
HTTP es un protocolo para transmitir páginas web, también conocidas como hipertexto en algunos ámbitos extraños. Se empezó a desarrollar en 1989 y como puedes imaginar, se implementa directamente sobre la capa de transporte del modelo OSI y es por ello que es responsable de manejar también sesión y presentación.
Por aquel entonces1, las páginas HTML que se transmitían por HTTP eran extremadamente simples, llamarlas hipertexto es casi una exageración, ni siquiera permitían incluir imágenes ni otro tipo de archivos, solamente enlaces, algo de formato y marcas para estructurar el texto.
Antes de ver qué es exactamente una cookie, debemos ver cómo funciona HTTP de forma básica. Imaginemos que vamos a abrir el contenido de un archivo, por ejemplo, el archivo humans.txt de Google, que se encuentra en la siguiente url: http://www.google.com/humans.txt. Al abrir el enlace, el navegador muestra el contenido del archivo de texto pero en realidad ha hecho alguna cosa más entre bambalinas, pero es transparente a ojos del usuario.
La conexión
Primero el navegador se conecta a www.google.com aprovechando las capacidades que la capa de transporte le brinda. En realidad, la capa de transporte no entiende de dominios, no sabe lo que significa google.com así que resuelve la dirección a la que conectarse preguntando a un servidor de nombres de dominio y obtiene la dirección IP de Google.
La petición
Una vez conectado a Google, el navegador le envía la siguiente línea de texto:
Esta primera línea es muy importante y tiene tres partes. La primera de ellas, en verde, es el verbo HTTP, en este caso GET que significa que quieres obtener algo del servidor. La segunda parte, en azul, es el recurso con el que se quiere interactuar. Al final, en naranja, el protocolo y la versión que se utiliza.
A continuación, el navegador envía algunas cabeceras, por ejemplo el formato que soporta, o la hora local. Por ejemplo:
Accept-Encoding: gzip, deflate, sdch
Accept-Language: es-ES,es;q=0.8
Host: www.google.com
User-Agent: Chrome/56.0.2924.87
En cada línea se envía una cabecera, que consta del nombre, seguido de dos puntos y después el valor.
Después de enviar las cabeceras, se envía una línea más en blanco y a partir de ahí Google nos debe enviar una respuesta.
La respuesta
En este punto, el servidor, en este caso Google, ha recibido la petición del navegador y empieza a escribir su respuesta:
La primera línea de la respuesta tiene tres partes. La primera, en naranja, la confirmación del protocolo y la versión del mismo. La segunda parte, en azul, el código de estado. Algunos códigos de estado que posiblemente conozcas son 404 (no encontrado) o 500 (error interno del servidor). Finalmente, en verde, una descripción textual breve del código de estado.
Date: Sun, 19 Feb 2017 20:57:48 GMT
Expires: Sun, 19 Feb 2017 20:57:48 GMT
Cache-Control: private, max-age=0
Last-Modified: Thu, 08 Dec 2016 01:00:57 GMT
Server: sffe
A continuación, el servidor envía una serie de cabeceras, que tienen el mismo formato de la petición. En estas cabeceras se indica, por ejemplo, la fecha y hora del servidor o el tipo del contenido que se está enviando.
Después de las cabeceras, se envía una línea en blanco y a partir de ahí el contenido de la respuesta. En este caso el contenido del archivo humans.txt:
La desconexión
Después del ciclo petición-respuesta se cierra la conexión. Si la página tuviera más recursos asociados, como imágenes, fuentes o estilos, se repetiría el ciclo completo por cada recurso.2
La capa de sesión
Fue aproximadamente en 1994 cuando alguien estaba programando una de las primeras tiendas online. Esa parte típica de las tiendas en las que tienes un carrito al que se van añadiendo productos a medida que se navega. El programador se dió cuenta de una de las enormes carencias de HTTP, al ser un protocolo pensado para descargar documentos de texto, no se necesitaba mantener ningún tipo de estado entre las distintas peticiones mientras se iba navegando, no implementaba la capa de sesión ni ningún mecanismo para mantener el estado entre peticiones.
Casualmente, este programador también trabajaba para Netscape Communications, el navegador predominante en la época, lo que le colocaba en una posición ventajosa para modificar el navegador y adaptarlo a sus necesidades: las cabeceras de cookie.
Estas cabeceras permitían al servidor almacenar información en el ordenador del usuario, y de esta forma facilitar enormemente la programación del carrito de la compra, almacenando temporalmente los artículos del carrito en cada uno de los ordenadores de los visitantes.
Las cabeceras cookie
Las cabeceras cookie consisten en una cabecera que envía el servidor, "Set-Cookie", para decirle al navegador lo que debe guardar, y una cabecera "Cookie" que envía el navegador para decirle al servidor lo que ha guardado.
La información que establece el servidor con Set-Cookie se envía en todas las peticiones siguientes por el navegador mediante la cabecera Cookie. De esta forma, en el carrito de la compra, cuando en la página de un artículo, por ejemplo un bolígrafo, y se navega a “Añadir artículo al carrito” el servidor enviaría “Set-Cookie: bolígrafo”, y el navegador enviaría “Cookie: bolígrafo” en todas las peticiones sucesivas. Si en la página de otro artículo, por ejemplo un cuaderno se navega a “Añadir artículo al carrito” el servidor enviaría “Set-Cookie: bolígrafo,cuaderno” y a partir de entonces, el navegador siempre enviará la cookie “Cookie: bolígrafo,cuaderno”.
De esta forma, mediante un par de cabeceras cookie, una de cliente y otra de servidor, disponemos de un mecanismo para mantener el estado entre peticiones independientes.
Conviene tener cuidado a la hora de almacenar información voluminosa en la cookie, ya que ésta información se reenvía en todas y cada una de las peticiones penalizando el rendimiento y aumentando el consumo de ancho de banda.
Además la cookie se puede enriquecer con otros atributos como la fecha de expiración, limitar su uso a un conjunto de sub rutas dentro de una URL, limitar al dominio o el tipo de cookie (de sesión o permanente).
Los dominios de las cookies
Cuando un sitio web almacena información mediante cookies en el ordenador de un usuario, esta cookie sólo se reenvía a las páginas del sitio web que la originó, es decir, cada sitio web puede almacenar su propia información en las cookies de forma aislada e independiente del resto de sitios web.
Seguridad y privacidad
En el caso del carrito de la compra, ¿qué consecuencias para la privacidad podrían tener unos cuantos artículos en una cookie? Recordemos que la información de la cookie se guarda en el ordenador del usuario y además se envía en todas y cada una de las peticiones al sitio web que la originó.
Actualmente las cookies que se guardan en el ordenador del usuario se cifran por el propio navegador. Cuando se envían por la red, si se envían por https no deberían poder interceptar la comunicación, al igual que cualquier otro tipo de información que podemos enviar como datos personales o contraseñas.